引言
Reinforcement Learning,简称RL,又称增强学习、强化学习等,是机器学习的一个分支,与有监督学习和无监督学习齐名。
RL是最符合AI本质的学习方式,与人一样,通过不断的与环境交互、尝试、试错、接收反馈、再去尝试等过程,来不断改进自身,真正具有自学习和成长能力。
较为经典的例子是Atari游戏,RL比人玩的要好,同时在棋牌类游戏也有较多应用和进展,比如AlphaGo就用到了RL。当然也有其他应用,比如控制领域、机器人等。
它的特点和不同点如下:
- 无监督,只有反馈
- 反馈会产生延迟
- 是与时间有关的序列
- 其行为会影响其后接收到的输入
重要概念
1. Reward
反馈。用于衡量做的好不好,是一个标量值。可简单的想象成游戏中的得分和失分,RL的目标就是最大化对应的累积反馈。
很多时候,反馈会产生延迟,现在的行为很可能会在以后很长一段时间才有反馈,这有点儿像人类的学习,可能要学很久才会有所回报。
2. Agent && Environment
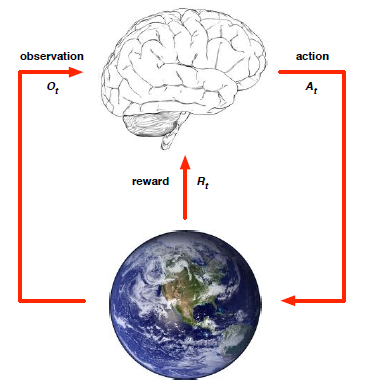
在时刻t,Agent(图中的大脑,可理解为RL学习者)
- 接收对环境的观察Ot
- 接收反馈Rt
- 做出反应At
在时刻t,Environment(图中的地球,可理解为环境)
- 接收Agent做出的反应或称行为At
- 产生下一时刻的观察Ot+1
- 产生下一时刻的反馈Rt+1
注意:t在环境阶段自增
3. State
状态。是历史的函数,历史是一串观察、反应、反馈序列Ht = O1, R1, A1, …, At-1, Ot, Rt。状态可用于决定下一时刻发生什么。
- 环境状态:是环境的内部表示,用于产生下一时刻观察和反馈,通常对RL学习者不可见
- RL学习者状态:是Agent的内部表示,用于产生当前时刻的反应
- 信息状态:包含历史中的所有有用信息,是马尔科夫状态,即下一时刻只与当前时刻有关,而与前面的时刻无关
由此产生两类环境:
- 全可观察:RL学习者直接观察到环境状态,Ot = St,信息状态 = 环境状态 = RL学习者状态,这即是马尔科夫决策过程MDP
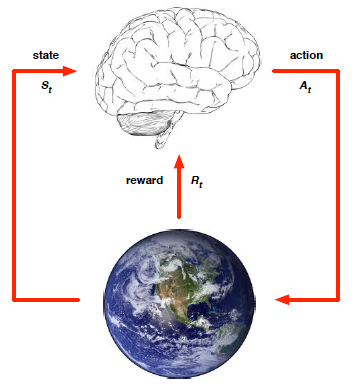
- 部分可观察:RL学习者只能观察到部分的环境状态,此时RL学习者状态 != 环境状态,是部分可见马尔科夫决策过程POMDP
主要组成部分
一个RL学习者(Agent),主要可由如下的一个或多个组成:
- Policy:是Agent的行为函数,从状态映射到反应。
- Value function:衡量当前状态加反应的好坏,从而用于选择下一个反应
- Model:Agent对环境的表示,用于预测环境下一时刻会怎么样
分类
RL学习者可有如下几种分类:
- Value-Based:无Policy,只有Value Function
- Policy-Based:只有Policy,无Value Function
- Actor-Critic:同时考虑Policy和Value Function
- Model-Free:有Policy/Value Function,无Model
- Model-Based:有Policy/Value Function,有Model
主要问题
- Learning:学习。环境刚开始未知,Agent通过与环境的交互不断学习,提升自己的Policy
- Planning:计划。环境模型已知,通过计算提升Policy,例如推理、思考、搜索等
- Exploration:探索。探索新方法,找出环境中的更多信息
- Exploitation:利用。利用经验,使反馈最大化
- Prediction:预测。对未来做估计,给出Policy
- Control:控制。对未来做优化,找到最佳的Policy